Python 的解释器有哪些?
- CPython:采用 C 语言开发的的一种解释器,目前最通用也是使用最多的解释器。
- IPython:是基于 CPython 之上的一个交互式解释器器,交互方式增强功能和 CPython 一样。
- PyPy:目标是执行效率,采用 JIT 技术。对 Python 代码进行动态编译,提高执行的速度。
- JPython:基于 Java 语言的解释器,可以直接将 Python 代码编译成 Java 字节码执行。
- IronPython:运行在微软 .NET 平台上的解释器,把 Python 编译成 .NET 的字节码,然后执行。
Python 3 和 Python 2 的区别?
print "hello"
# 在py2中,print是语句
# python2.6+ 可以使用 from __future__ import print_function 来实现相同功能,将print当作函数使用
print("hello")
# 在py3中,print是函数
编码
# py2默认编码是ascii,一般在文件顶部需要加 coding:utf-8
# >>> import sys
# >>> sys.version
'2.7.16 (default, Feb 28 2021, 12:34:25) \n[GCC Apple LLVM 12.0.5 (clang-1205.0.19.59.6) [+internal-os, ptrauth-isa=deploy'
# >>> sys.getdefaultencoding()
'ascii'
# py3默认是utf-8
# >>> import sys
# >>> sys.version
'3.8.2 (default, Apr 8 2021, 23:19:18) \n[Clang 12.0.5 (clang-1205.0.22.9)]'
# >>> sys.getdefaultencoding()
'utf-8'
字符串
# py2中字符串有两种类型,unicode文本字符串和str字节序列
# 字符串格式化方法 %
age = 18
print("%s" % age)
# py3中字符串是str,字节序列是byte
# 字符串格式化方法 format
age = 18
print("{0}".format(age))
# py3新的格式化输出方式 f-string
print(f"{age}")
True和False
- py2:True和False是两个全局变量,分别对应1和0,既然是变量,那么他们就可以指向其它对象,可以被重新赋值
- py3:修复了这个缺陷,True和False变成了两个关键字,永远指向两个固定的对象
迭代器
# py2:很多内置函数和方法都是返回列表对象
# py3:全都更改成了返回迭代器对象,因为迭代器的惰性加载特性使得操作大数据更有效率
# py2的range和xrange函数合并成了range,如果想同时兼容py2和py3,可以这样写:
try:
range = xrange
except:
pass
# 另外字典对象的dict.keys()和dict.values()方法不再返回一个列表,而是以一个迭代器的'view'的对象返回,
# 高阶函数map,filter,zip返回的也不是列表对象了,
# py2的迭代器必须实现next方法
# py3则是__next__方法
nonlocal
# py2:
# 在函数里面,可以用关键字global声明某个变量为全局变量,但是在嵌套函数中是没法实现的
name_x = "tomtao"
def hello_x():
def update_name_x():
global name_x
name_x = "9527"
update_name_x()
print(name_x) # name依旧是"tomtao"
# py3:
# 可以使用关键字nonlocal实现,使得在嵌套函数中非局部变量成为可能。
name_y = "tomtao"
def hello_y():
def update_name_y():
nonlocal name_y
name_y = "9527"
update_name_y()
print(name_y) # name="9527"
除法符号 /
- py2:除法/的返回的结果是整型;
- py3:返回的结果是浮点类型。
声明元类
# py2:
class newclass:
_metaclass_ = MetaClass
# py3:
class newclass(metaclass=MetaClass):
pass
异常
py2:
except Exception, var:
pass
py3:
except Exception as var:
pass
自定义自己的异常
- 继承自Exception即可
class MyException(Exception):
pass
try:
raise MyException('my exception')
except MyException as e:
print(e)
不等运算符
- py2:!= <>
- py3:!= 去掉了<>
经典(旧式)类和新式类
# py2:
# 默认都是经典(旧式)类,只有继承了object才是新式类,有以下三种写法:
#新式类写法
class Test(object):
pass
#经典(旧式)类
class Test:
pass
class Test():
pass
# py2中新式类和经典(旧式)类的区别:
# 经典(旧式)类采用的是深度优先算法,当子类继承多个父类时,如果继承的多个父类有属性相同的,根据深度优先,会以继承的第一个父类的属性为主;
# 新式类采用的是广度优先算法,当子类继承多个父类时,如果继承的多个父类有属性相同的,根据广度优先,后面继承的属性会覆盖前面已经继承的属性。
# py3:
# 默认都是新式类,并且不必显式的继承object,有以下三种写法:
class Test(object):
pass
class Test:
pass
class Test():
pass
Python3 和 Python2 中 int 和 long 区别
- py2:有int和long类型。int类型最大值不能超过 sys.maxint,而且这个最大值是平台相关的。可以通过在数字的末尾附上一个L来定义长整型,它比int类型表示的数字范围更大。
- py3:只有一种整数类型int,大多数情况下,和Python2中的长整型类似。
xrange 和 range 的区别
- py2:xrange 是在 Python2 中的用法,
- py3:只有range,xrange用法与range完全相同,所不同的是生成的不是一个list对象,而是一个生成器。
鸭子类型
鸭子类型更多关注的是接口而非类型
class Duck:
def quack(self):
print("gua gua")
class Person:
def quack(self):
print("我是人类,但我也会gua gua gua")
def in_the_forest(duck):
duck.quack()
def game():
donald = Duck()
john = Person()
in_the_forest(donald)
in_the_forest(john)
print(type(donald))
print(type(john))
print(isinstance(donald, Duck))
print(isinstance(john, Person))
game()
# gua gua
# 我是人类,但我也会gua gua gua
# <class '__main__.Duck'>
# <class '__main__.Person'>
# True
# True
monkey patch
什么是monkey patch
- 运行时属性替换
- 比如gevent库需要修改内置的socket
import socket
print(socket.socket)
from gevent import monkey
monkey.patch_socket()
print(f"after monkey patch----{socket.socket}")
import select
print(select.select)
monkey.patch_select()
print(f"after monkey patch----{select.select}")
# <class 'socket.socket'>
# after monkey patch----<class 'gevent._socket3.socket'>
# <built-in function select>
# after monkey patch----<function select at 0x10e57ba60>
哪些地方会用到monkey patch
- socket
- select
自己如何实现
# 比如替换time
import time
print(time.time()) # 应该是打印时间戳
# 可以定义一个方法 替换其time()
def _time():
return 1234566
time.time = _time
print(time.time())
# 1621059653.7665548
# 1234566
自省
- 运行时判断一个对象的类型的能力
- 通常使用 isinstance, id, type获取对象类型信息
- Inspect模块提供了更多获取对象信息的函数
Python如何传递参数
一个很容易混淆的问题
- 是引用传递还是值传递?都不是。唯一支持的参数传递是共享传参
- Call by Object (Call by Object Reference or Call by Sharing)
- Call by sharing (共享传参)。函数形参获得实参中各个引用的副本
- 不可变类型是只拷贝了一个新对象 并指向它
- 可变类型是对原对象的引用
- int/float/bool/tuple/str/frozenset 都是不可变类型
- list/set/dict 都是可变类型
def testA(l):
l.append(0)
print(l)
def testB(s):
s += 'a'
print(s)
l = list()
testA(l)
testA(l)
s = 'hello'
testB(s)
testB(s)
# [0]
# [0, 0]
# 'helloa'
# 'heeloa'
def testC(ll1):
ll1 = []
ll = [1, 2, 3]
testA(ll)
print(ll)
# [1,2,3]
# 默认参数只计算一次
def testD(ll2=[1]):
ll.append(1)
print(ll)
testD()
testD()
# [1,1]
# [1,1,1]
Python性能优化及GIL
什么是Cpython GIl
GIT - Global Interpreter Lock
- Cpython解释器的内存管理并不是线程安全的
- 保护多线程情况下对Python对象的访问
- Cpython使用简单的锁机制避免多个线程同时执行字节码
GIL的影响
- 同一时间只能有一个线程执行字节码
- CPU密集型程序难以利用多核优势
- IO期间会释放GIL,对IO密集型程序影响不大
如何规避GIL影响
- CPU密集型可以使用多进程+进程池
- IO密集型使用多线程/协程
- cython扩展
如何剖析程序性能
使用各种profile工具(内置或第三方)
- 2/8定律 大部分时间消耗在少量代码上
- 内置的profile/cprofile等工具
- web应用可考虑使用pyflame(uber开源)的火焰图工具
服务端性能优化措施
web语言一般不会成为瓶颈
- 数据结构和算法
- 数据库层:索引优化 慢查询消除 批量操作减少IO NOSQL
- 网络IO:批量操作 pipeline操作 减少IO
- 缓存:使用内存数据库redis/memcached
- 异步:asynsio celery
- 并发:gevent/多线程
Python深拷贝和浅拷贝
# 存在一个list
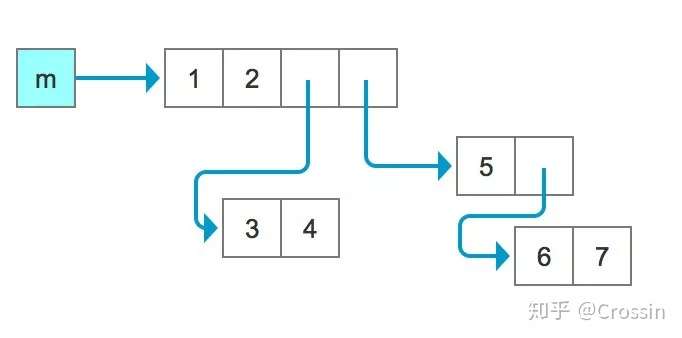
m = [1, 2, [3, 4], [5, [6, 7]]]
- 为了表示地更直观,用图描述下
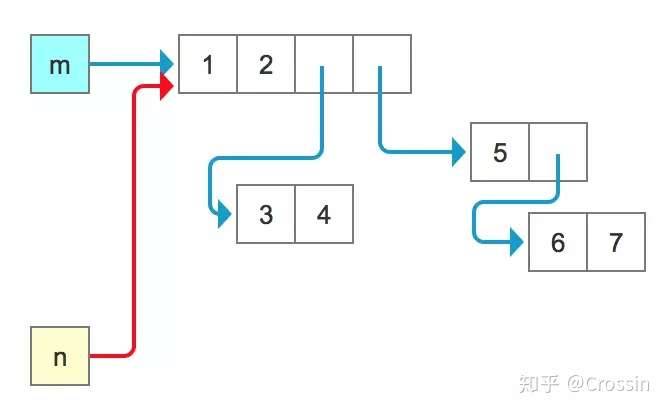
- 现在我们想要再来“复制”一个同样的变量,可以直接 n = m
- 但是这里的赋值只是相当于增加了一个标签,没有新的对象产生,如下图所示
- 用id()验证你会发现,m和n仍然还是一个东西,内部的元素依旧是一样的,对其中一个元素进行修改,另一个也会对应变化
m = [1, 2, [3, 4], [5, [6, 7]]]
n = m
m.append(666)
print(f"m_id:{id(m)}") # m_id:4340932672
print(f"n_id:{id(n)}") # n_id:4340932672
print(f"m_val:{m}") # m_val:[1, 2, [3, 4], [5, [6, 7]], 666]
print(f"n_val:{n}") # n_val:[1, 2, [3, 4], [5, [6, 7]], 666]
print(n is m) # True
- 这种操作一般也叫’旧瓶装旧酒’,只是多贴了一层标签(给m所对应的内存地址贴了一个n的标签),而我们是要得到一个对象的拷贝,就需要使用copy()
from copy import copy
m = [1, 2, [3, 4], [5, [6, 7]]]
print(f"m_id:{id(m)}") # m_id:4301943168
print(f"m_val:{m}") # m_val:[1, 2, [3, 4], [5, [6, 7]]]
print([id(i) for i in m]) # [4298689264, 4298689296, 4301922880, 4301924160]
n = copy(m)
print(f"n_id:{id(n)}") # n_id:4301925120
n.append(9527)
print(f"n_val:{n}") # n_val:[1, 2, [3, 4], [5, [6, 7]], 9527]
print([id(i) for i in n]) # [4515756784, 4515756816, 4518986304, 4518987584, 4517215920]
print(n is m) # False
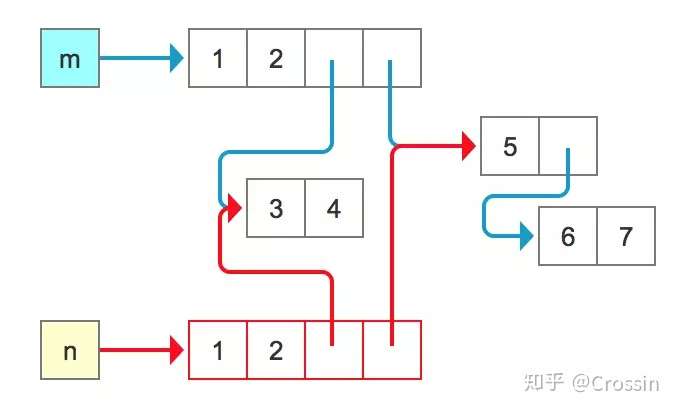
- 从结果中可以看出,m和n已不是同一个对象,对列表n中某些元素的重新赋值并不会影响原有对象m,但是其内部元素的id值还是一样的,
- 所以对一个可变类型元素的修改,仍然会反应在愿对象中。如下图所示
- 其实1,2还是指向同一个对象,但作为不可变对象来说,他们互不影响,感觉就是复制类一份而已。
- 这种复制方法叫浅拷贝,也叫’新瓶装旧酒’,虽然产生了新对象,但是内容还是来自同一处。
- 如果要产生一个原对象完全隔离的新对象,就需要使用深拷贝。deepcopy()
from copy import deepcopy
m = [1, 2, [3, 4], [5, [6, 7]]]
print(f"m_id:{id(m)}") # m_id:4479422592
print(f"m_val:{m}") # m_val:[1, 2, [3, 4], [5, [6, 7]]]
print([id(i) for i in m]) # [4476168944, 4476168976, 4479402304, 4479403648]
n = deepcopy(m)
print(f"n_id:{id(n)}") # n_id:4479404608
n.append(9527)
print(f"n_val:{n}") # n_val:[1, 2, [3, 4], [5, [6, 7]], 9527]
print([id(i) for i in n]) # [4476168944, 4476168976, 4479511488, 4479512064, 4477628080]
print(n is m) # False
print(m) # [1, 2, [3, 4], [5, [6, 7]]]
print(n) # [1, 2, [3, 4], [5, [6, 7]], 9527]
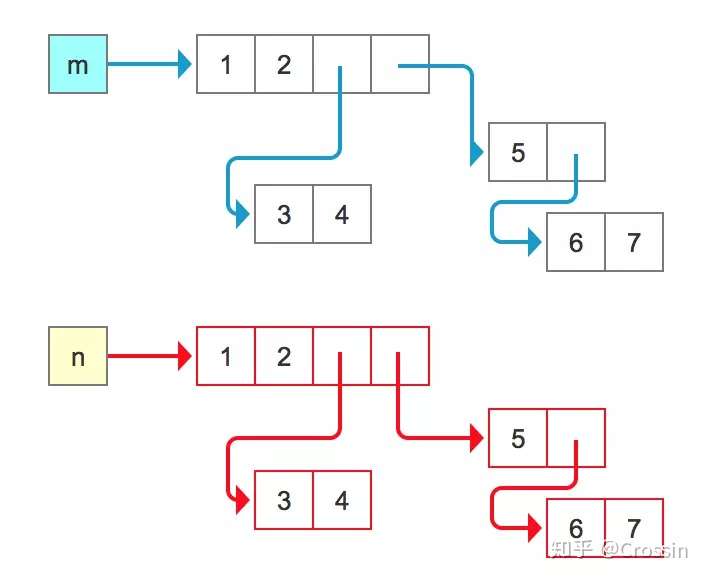
- 此时对新对象任意元素进行修改都不会影响愿对象,新对象中的子列表,无论有多少层,都是新对象,有自己的不同的地址。如下图所示
- 这种操作一般也叫做’新瓶装新酒’,你可能会注意到一个细节:n 中的前两个元素的地址仍然和 m 中一样。这是由于它们是不可变对象,不存在被修改的可能,所以拷贝和赋值是一样的。
- 深拷贝也可以理解为,不仅是对象自身的拷贝,而且对于对象中的每一个子元素,也都进行同样的拷贝操作。这是一种递归的思想。
- 深拷贝的实现过程并不是完全的递归,否则如果对象的某级子元素是它自身的话,这个过程就死循环了。实际上,如果遇到已经处理过的对象,就会直接使用其引用,而不再重复处理。
- 看一个例题,会输出啥
from copy import deepcopy
a = [3, 4]
m = [1, 2, a, [5, a]]
n = deepcopy(m)
n[3][1][0] = -1
print(n) # # [1,2,[-1,4],[5,[-1,4]]]
- deepcopy()对各层元素都会建立副本,所以m[2]和m[3][1]指向的都是list对象[3, 4]的副本,而非本体。所以m[2]和m[3][1]和原本的list对象[3, 4]以及a都没有关系了
Python如何正确初始化一个二位数组
# 创建一个数组,全部元素都为1的二维数组 3*2 [[1]*col for i in range(row)]
col = 3
row = 2
array = [[1]*col for i in range(row)]
print(array) # [[1, 1, 1], [1, 1, 1]]
array[0][1] = 666
print(array) # [[1, 666, 1], [1, 1, 1]]
# 这种写法是错误的 [[0] * col] * row
array2 = [[1]*col]*row
print(array2) # [[1, 1, 1], [1, 1, 1]]
array2[0][1] = 666
print(array2) # [[1, 666, 1], [1, 666, 1]]
- 虽然二者都可以生成二维数组,但是第二种写法,这样每行创建的是 [0]*col的引用,array2[0] == array[2],对其中一个子数组的修改,会影响到另一个子数组,如上面代码所示。
全菊变量和菊部变量
- 先看一段代码
def func(x):
print(f"x={x}")
y = 10
x += y
print(f"x={x}")
a = 5
b = func(a)
print(f"a={a}")
print(f"b={b}")
# 打印结果
# x=5
# x=25
# a=5
# b=25
- 这里,函数 func 的形参是 x,它只在函数内部有效,也就是作用域仅在函数中,如果在外部调用它,就会报错。
- 变量 a 作为实参传递给函数 func,所以函数里 x 的值就是 a 的值,但 x 不是 a,只是现在它俩一样。
- 变量 y 是函数中定义的局部变量,它的作用域同样也仅在函数中。
- 对 x 进行赋值之后,x 的值发生了变化,但不会影响实参 a 的值。
- 函数的返回值是 x 的值,并赋值给了外部的变量 b,所以 b 的值就是 x 的值,但 b 不是 x,此时 x 已不存在。
- 再看一段代码
def func(x):
print(f"x={x}")
y = 10
x += y
print(f"x={x}")
a = 5
func(a)
print(f"a={a}")
# 打印结果
# x=5
# x=20
# x=5
- 函数 func 的形参是 x。
- 外部变量 x 作为实参传递给函数 func,所以函数里 x 的值就是外部 x 的值,但这两个 x 是两个不同的变量,只是现在值一样。
- 变量 x 在函数中被重新赋值 10,但不会影响外部变量 x 的值。
- 对 x 自身做了累加,此时 x 变成 20。
- 函数的返回值是 x 的值,但没有赋值给任何变量,所以此返回值没任何作用,函数结束。
- 外部的变量 x 仍然是一开始的值 5。
- 如果要在函数内部修改外部的变量可不可以呢?可以使用全局变量 global
def func():
global x
x = 666
x = 9527
func()
print(f"x={x}") # x=666
- 在函数中声明 global x,程序就会知道这个 x 是一个全局变量。此时的 x 就是外部的 x,给它赋值的结果自然在函数结束后依然有效。
- 但这种情况下,你不能再同时将 x 设定为函数的形参。
- 如果你仅仅需要在函数内部读取外部的参数值而不用修改它的值,那么 global 的声明就不再需要。
def func():
y = x
print('y =', y)
x = 5
func()
print('x =', x)
# 打印结果
# y = 5
# x = 5
- 写入时 global 的必要在于区分全局变量和局部变量,而读取不存在这样的问题。
Python函数参数传递
- 看一段代码,输出结果是啥?
def func(m):
m[0] = 9527
m = [4,5,6]
return m
l = [1,2,3]
func(l)
print(f"l = {l}") # l = [9527, 2, 3]
- 很多人会好奇,为什么不是[4,5,6],而是[9527,2,3],python官方文档,有一句标识:(Remember that arguments are passed by assignment in Python.)要记住,Python 里的参数是通过赋值传递的。
- 在很多人的直观印象里,变量是一个容器,给一个变量赋值,就是往一个存储的容器里填入一条数据,再次赋值就是把容器里对应的数据替换掉。
- 然而,在Python中,这种理解是错误的。
- 比较形象的类比就是:python中的变量更像是一个标签,给变量赋值,就是把一个标签贴在一个物体上。再次赋值就是把标签贴在另一个物体上。
- 体会这两种设计的差异:
- 前者,变量是一个固定的存在,赋值只会改变其中的数值,而变量本身没有改动。
- 后者,变量不存在实体,它仅仅是一个标签,一旦赋值就被设置到另一个物体上,不变的是那些物体。
- 这些物体就是对象,在Python中,一切皆是对象,函数/类/模块/字符串等都是对象。
a = 1
b = 2
c = 1
# 再次赋值
a = b
- 在这个代码里,a和c指向的都是同一个对象整数1,给a赋值为b之后,a就变成了指向对象整数2的标签,但1和c都不会受到影响。如下图所示
- 再次验证
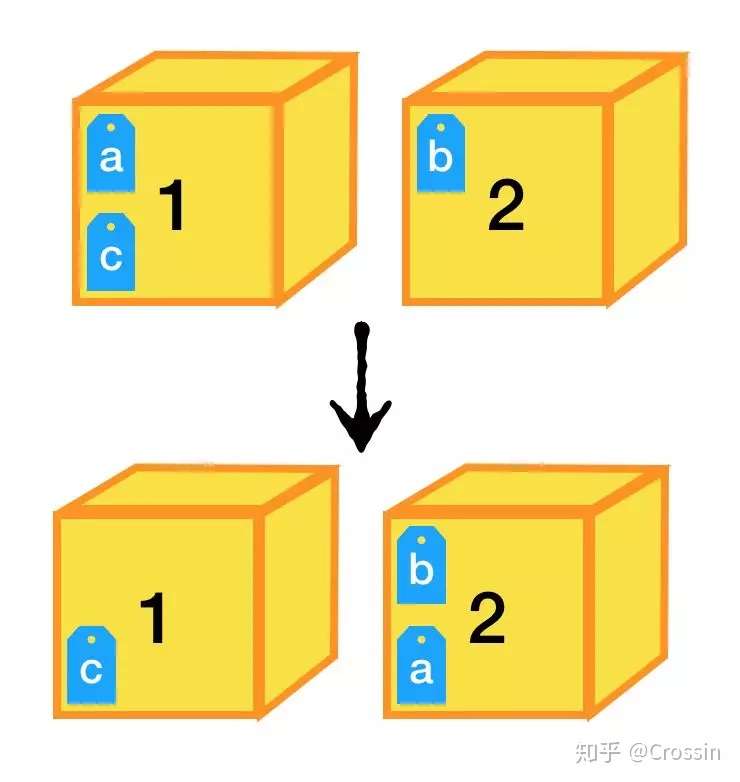
a = 1
print('a', a, id(a))
b = 2
print('b', b, id(b))
c = 1
print('c', c, id(c))
# 再次赋值
a = b
print('a', a, id(a))
# 打印结果
# a 1 4379831024
# b 2 4379831056
# c 1 4379831024
# a 2 4379831056
- id() 可以认为是获取一个对象的地址。可以看出,a 和 c 开始其实是同一个地址,而后来赋值之后,a 又和 b 是同一个地址。
- 每次给变量重新赋值,它就指向了新的地址,与原来的地址无关了。
- Python 里的参数是通过赋值传递的 看一段代码
def fn(x):
x = 3
a = 1
fn(a)
print(a)
# 打印结果
# 1
- 调用fn(a)时,相当于做了一次赋值操作,把a赋值给x,也就是把x这个标签贴在了a这个对象上,只不过x的作用域仅限于函数fn()内部。
- 所以,当 x 在函数内部又被赋值为 3 时,就是把 x 又贴在了 3 这个对象上,与之前的 a 不在有关系。所以外部的 a 不会有任何变化。
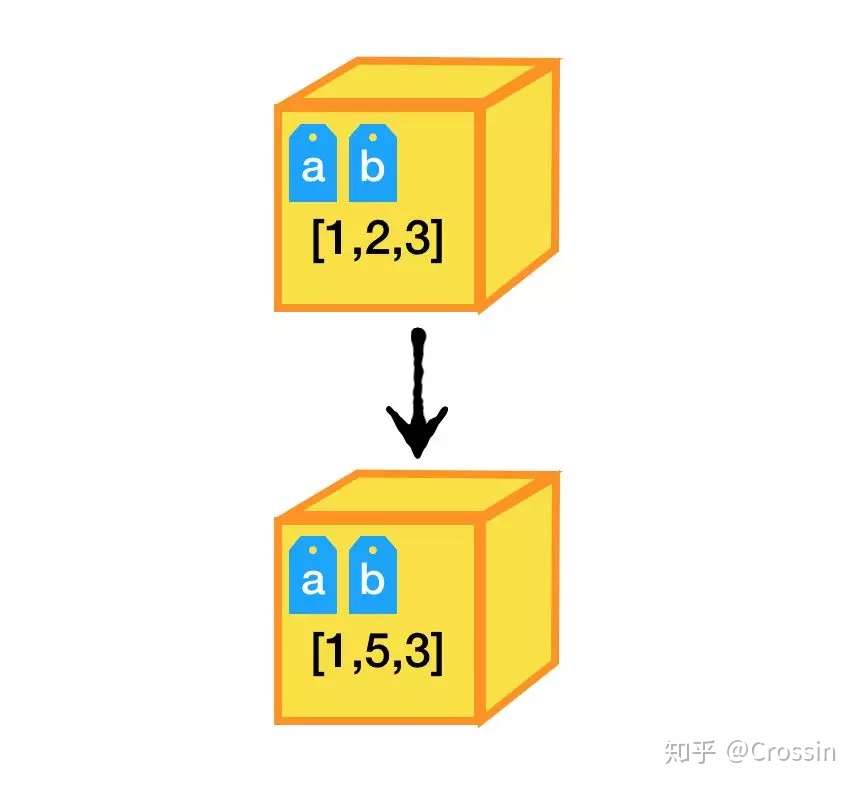
- 再看一段代码
a = [1,2,3]
print('a', a, id(a))
b = a
print('b', b, id(b))
b[1] = 5
print('a', a, id(a))
print('b', b, id(b))
# 打印结果
# a [1, 2, 3] 4389822656
# b [1, 2, 3] 4389822656
# a [1, 5, 3] 4389822656
# b [1, 5, 3] 4389822656
- 当b赋值为a后,a和b都指向同一个列表对象,基于index进行赋值是对对列表list对象本身进行操作,改变的是对象本身,并没有给b重新贴标签。所以b和a都指向的原来的list对象。如下图所示
- 再看开头的问题
def func(m):
m[0] = 20
# m = [4, 5, 6]
return m
l = [1, 2, 3]
func(l)
print('l =', l)
- 去掉那句 m=[4,5,6] 的干扰,函数的调用就相当于:
l = [1, 2, 3]
m = l
m[0] = 20
- l 的值变成 [20,2,3] 没毛病吧。而对 m 重新赋值之后,m 与 l 无关,但不影响已经做出的修改。
- 另外说下,函数的返回值 return,也相当于是一次赋值。只不过,这时候是把函数内部返回值所指向的对象,赋值给外面函数的调用者:
def fn(x):
x = 3
print('x', x, id(x))
return x
a = 1
a = fn(a)
print('a', a, id(a))
# 打印结果
# x 3 4406274864
# a 3 4406274864
- 函数结束后,x 这个标签虽然不存在了,但 x 所指向的对象依然存在,就是 a 指向的新对象。
- 通俗解释—第二个人被取名和第一个人相同,并不等于第一个人就变成了第二个人。
所以,如果你想要通过一个函数来修改外部变量的值,有几种方法:
- 通过返回值赋值
- 使用全局变量
- 修改 list 或 dict 对象的内部元素
- 修改类的成员变量